Parameter search 參數搜尋 #
每個模型多少都會有一些參數由使用者選擇,選擇好的參數對模型來說非常重要。通常重要的參數一定要做調整,次要的參數則是調不調都可以。通常在搜尋參數的時候會留一個獨立於訓練資料的 validation set,常是多個參數,然後觀察 validation set 的分數來決定這個參數好不好。
搜尋範圍 #
多數參數都是整數、正整數、實數或是正實數,沒有辦法看過所有參數,然後找一個最好的。通常我們會設定一個搜尋範圍,比如說 0 到 10,跑過 0、2、4、6、8、10,找一個最好的。但如果模型要跑很久,例如深度學習模型,我們通常會一次找十倍,比較有效率,如學習率 0.0001、0.001、0.01、0.1……找出比較好的區間以後,再到該區間細調。
搜尋邊界 #
承上,如果最好的參數是在我們搜尋範圍的邊界,例如學習率 0.0001,那我們會再往外找 0.00001,直到變差為止。避免離最好的參數還很遠的時候就停下來。
Random search vs Grid search #
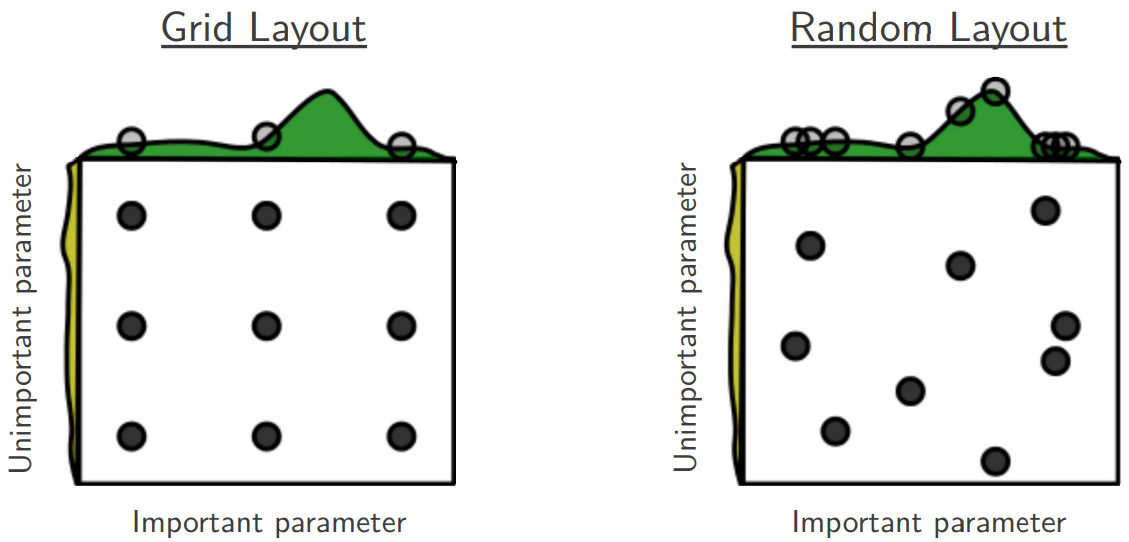
在 Bergstra 與 Bengio 發表在 Journal of Machine Learning Research 2012 的論文 Random Search for Hyper-Parameter Optimization 指出 random search 比 grid search 更有效率。下圖為論文中的圖片,黑色圓點是測試的參數分佈。
Bayesian Hyperparameter Optimization 貝式參數最佳化 #
貝式參數最佳化是一個機器學習的研究領域,主要為在平衡探索未知參數與保留已知最佳參數 (exploration - exploitation trade-off) 的情況下,想辦法找出成效最好的參數組合。現有的套件如 Spearmint、SMAC 或是 HyperOpt。但一般情況下,在有經驗者選擇適當的參數區間時,這些套件跟 random search 或 grid search 相比並沒有特別的優勢。
不同模型的重要參數 #
不同模型會有不同的重要參數需要調整 (但不代表不重要的參數就不用調),以下列舉幾種模型:
- Logistic regression:Regularization term 的強度,Scikit Learn 套件裡面的 C。
- 決策樹、梯度提升決策樹 (GBDT) 等基於決策樹的模型:樹的最大深度。
- 深度學習模型:通常來說,訓練一個架構已經固定的模型,最重要的參數就是初始的學習率 (learning rate) 跟 learning rate decay schedule (如果有的話)。
- Word2vec、DeepWalk 等基於 Word2vec 的模型:決定 positive pairs 的 window size。
參考資料: CS231n 參數最佳化